지정한 job만 실행될 수 있도록 application.yml에는 아래 내용을 추가
spring:
batch:
job:
names: ${job.name:NONE}main 함수에는 아래와 같은 job이 실행된 다음 종료될 수 있는 코드를 추가하였다.
ConfigurableApplicationContext applicationContext = SpringApplication.run(TestBatchApplication.class, args);
System.exit(SpringApplication.exit(applicationContext));
Dashboard > Jenkins관리 > Configure System 에서 아래의 설정을 해준다.
1. Global properties (jar위치, jvm 옵션 등등)

2. Build Timestamp
Timestamp 플러그인을 다운 받아 아래와 같이 설정
Jenkins에서 Freestyle Project를 선택해서 shell script를 실행하게 하였고,
AWS EC2에 있는 jar 파일을 직접 실행하게끔 하였다.
지정한 jar파일에 접근할 수 있도록 권한 주기
sudo chown -R ec2-user:ec2-user /var/lib/jenkins/workspace/
위에서 구성한 Jenkins Project들의 이름은 Pipeline 스크립트에서 사용된다.
파이프라인 설정
Pipeline 아이템 추가
파이프라인을 설정해주는데 나중에는 Trigger는 'Build periodically'를 선택해 일정 주기로 실행될 수 있게 해줄 것이다.
파이프라인 스크립트는 아래와 같이 간단하게 작성해본다.

pipeline {
agent none
stages {
stage('a') {
steps {
build 'ATargetJob'
}
}
stage('b') {
steps {
build job: "BTargetJob", wait : true
}
}
stage('c') {
steps {
build job: "CTargetJob", wait : true
}
}
stage('d') {
steps {
build job: "DTargetJob", wait : true
}
}
}
}
순차적으로 a->b->c->d가 실행되고, 중간에 실패되면 pipeline은 중지된다.
AWS EC2 환경에 설치된 Jenkins로 실행하다 보니 로컬 환경에서와는 달리 실패되는 부분이 있었고, 결국 11번의 시도 끝에 pipeline이 정상적으로 실행되었다.
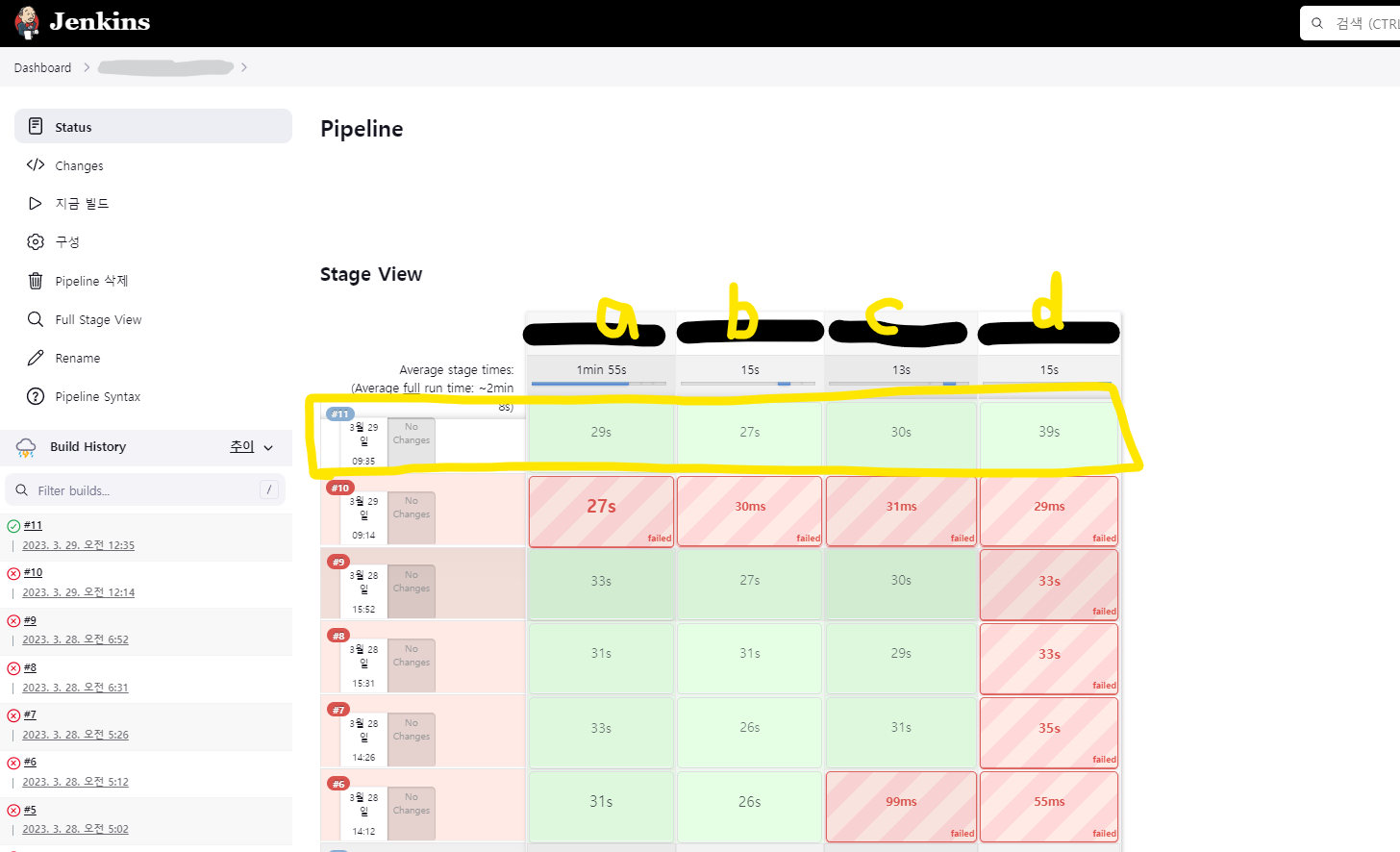
이제 큰 틀은 짰으니 세세한 부분을 신경쓰러 떠나보겠다...
'스프링 > Spring Batch' 카테고리의 다른 글
| Spring Cloud Data Flow & Spring Batch 사용 (실패), docker-compose 파일 (0) | 2023.03.22 |
|---|---|
| Spring Batch를 사용하며 맞닥뜨린 상황 기록 02 (0) | 2023.02.28 |
| Spring Batch를 사용하며 맞닥뜨린 상황 기록 01 (0) | 2023.02.14 |
| 스프링배치 핵심 개념 체크를 위한 Questions (메타데이터 테이블, skip&retry, chunk oriented, cursor & paging 등) (0) | 2022.11.16 |
| Spring Batch - @JobScope, @StepScope / LocalDate 사용법 (0) | 2022.10.25 |