사수님은 Map을 함부로 쓰지 말라는 충고를 자주 해주셨다.
Map의 무분별한 활용으로 Memory Leak이 운영중인 서비스에 발생할 수 있다 하셨다.
그래서 오늘 스터디 내용의 주제는 Map이다. 몸은 가까웠지만 마음은 멀었던 요놈, 파헤쳐보기로..
아래 내용은 기술 세미나(?)를 위해 내가 준비한 자료들이다.

인터페이스 List와 Set을 구현한 컬렉션 클래스들은 많은 공통부분이 있어서,
공통된 부분을 다시 뽑아 Collection 인터페이스를 정의할 수 있었지만
Map인터페이스는 이들과는 다른 형태로 컬렉션을 다루기 때문에 같은 상속 계층도에 포함되지 못한다.

HashMap은 Entry 타입을 구현한 Node라는 내부 클래스를 정의하며
키와 값은 별개의 값이 아니라 서로 관련된 값이기 때문에 하나의 클래스로 정의하여 하나의 배열로 다룬다.
키와 벨류는 Object 타입이므로 어떠한 객체도 저장할 수 있다.
Node 클래스 자체는 사실상 Java 7의 Entry 클래스와 내용이 같지만,
Java 8에서는 일정 개수 이상이 되면 트리구조를 이용하는 것으로 발전했다.
링크드 리스트 대신 트리를 사용할 수 있도록 하위 클래스인 TreeNode가 있다는 것이 Java 7 HashMap과 다릅니다.

해싱에서 사용하는 자료구조는 배열과 링크드 리스트의 조합으로 되어있다.
저장할 데이터의 키를 해시함수에 넣으면 배열의 한 요소를 얻게 되고,
다시 그곳에 연결되어 있는 링크드 리스트에 저장한다.
예를 들면 주민등록번호의 맨 앞자리인 생년을 기준으로 데이터를 분류해서 10개의 서랍에 나눠담는다.
71,72년생과 같은 70년대 환자들의 데이터는 같은 서랍에 저장하는 식으로
이렇게 분류하여 저장하면 환자의 주민번호로 태어난 년대를 계산해서 어느 서랍에서 찾아야 할지를 쉽게 알 수 있다.
링크드리스트는 크기가 커질수록 검색속도가 떨어지기 때문에
하나의 서랍에 데이터의 수가 많을수록 검색에 시간이 더 걸린다.
배열은 배열의 크기가 커져도,
원하는 요소가 몇 번째에 있는지만 알면 아래의 공식에 의해서 빠르게 원하는 값을 찾을 수 있다.
링크드리스트는 불연속적으로 존재하는 데이터를 서로 연결한 형태로 구성되어 있는데,
리스트의 각 요소(node)들은 자신과 연결된 다음 요소에 대한 참조(주소값)와 데이터로 구성되어 있다.
연속적으로 메모리상에 존재하는게 아니기 때문에
링크드리스트는 불연속적으로 위치한 각 요소들이 서로 연결된 것이라
처음부터 n번째 데이터까지 차례대로 따라가야만 원하는 값을 얻을 수 있다.
그래서 데이터의 개수가 많아질수록 데이터를 읽어 오는 시간이 길어진다는 단점이 존재
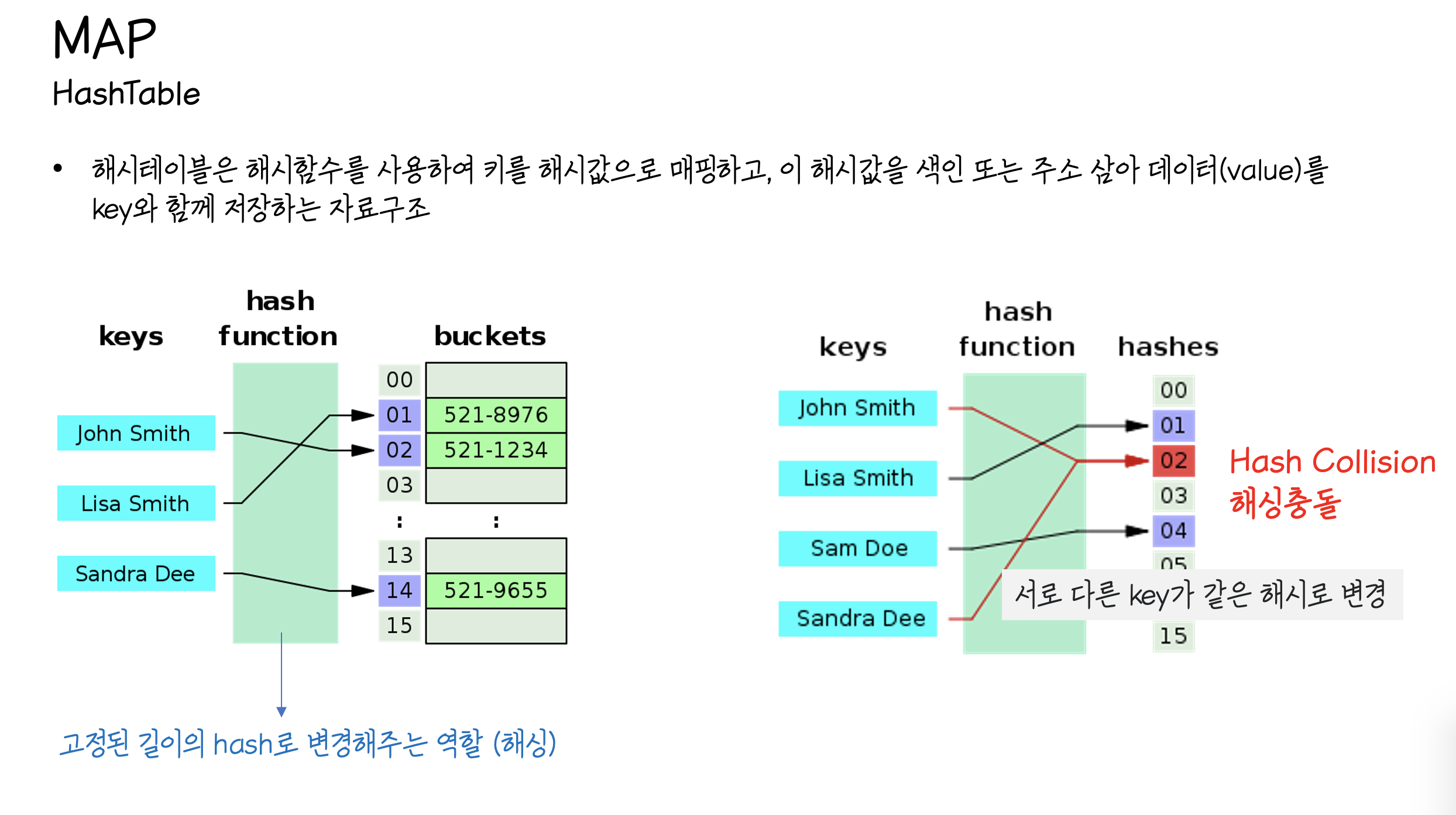
키를 있는 그대로 저장하는 경우 다양한 키의 길이 만큼의 크기를 마련해두어야 하기 때문에
일정한 길이의 해시로 변경해야 한다고 했다.
키의 전체 개수와 동일한 크기의 버킷을 가진 해시테이블을 Direct-address table라고한다.
Direct-address table의 장점은 키의 개수와 테이블의 크기가 같기 때문에
해시 충돌 문제가 발생하지 않는다다.
Q. 실제 사용하는 키는 몇개 되지 않을 경우에는?
- 전체키 100개중에 실제로는 10개의 키만 사용하는데 100개 크기의 테이블을 유지하고 있는 것은 메모리 낭비이다.
따라서 보통의 경우 실제 사용하는 키 개수보다 적은 해시테이블을 운용한다고 한다.
그렇기에 해시 충돌이 발생할 수 밖에 없고, 해시 충돌을 해결하기 위한 다양한 방법들이 고안되었다.
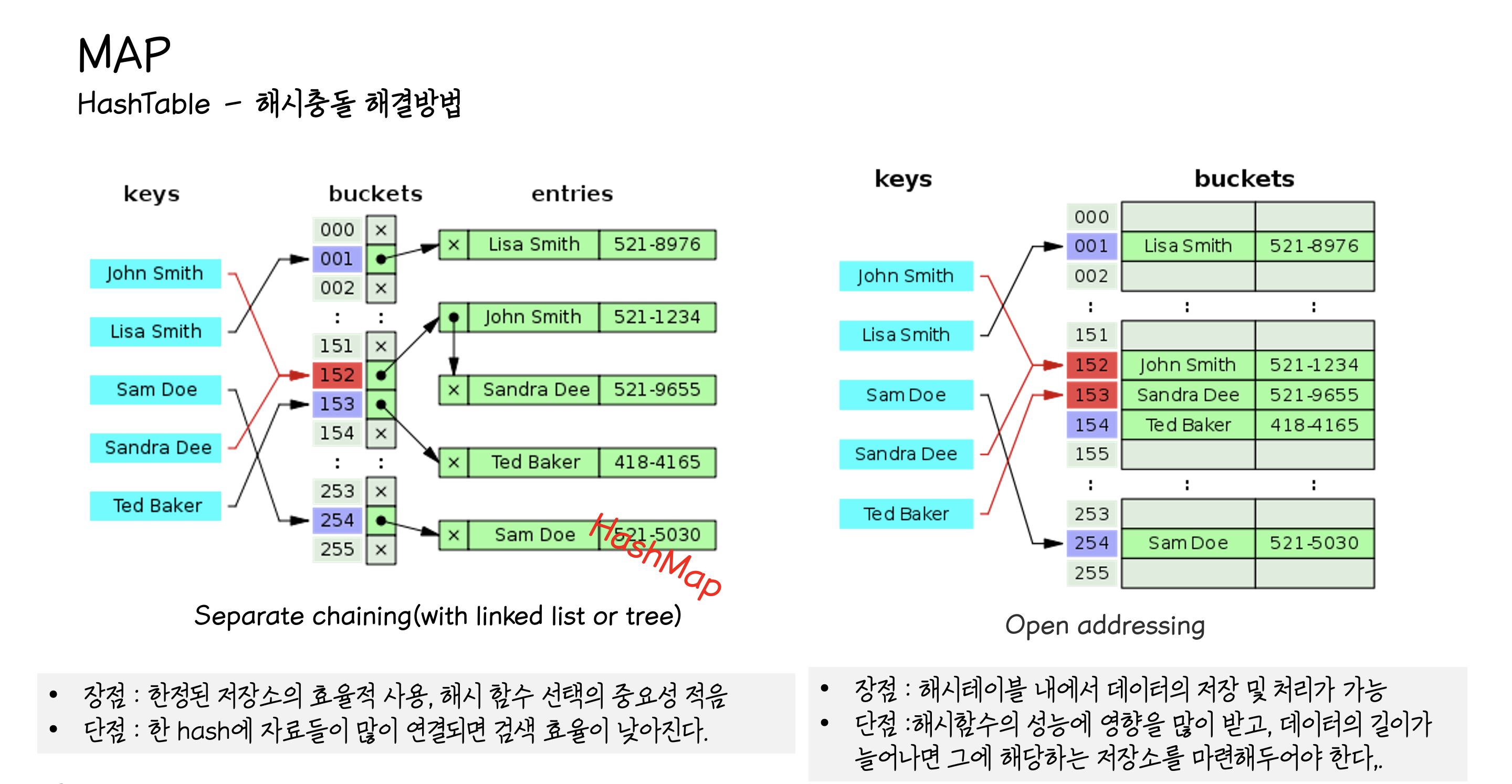
둘 이상의 키에 동일한 인덱스 충돌이 발생할 경우 해결방법에 따라 크게 두가지 형태로 나눈다.
첫번째로는 Separate chaning으로 충돌 발생시 링크드 리스트로 연결하는 방식으로 간단한 해시 함수를 사용하기 때문에 가장 널리 쓰이는 방식. Java HashMap에서 이용하는 방식으로 동일한 버킷의 데이터에 대해 리스트 혹은 트리 자료구조를 이용해서 추가 메모리를 사용하여 다음 데이터의 주소를 저장한다. HashMap은 리스트의 개수가 8개 이상이 되면 트리 자료구조를 사용하게 된다.
두번째는 OpenAddressing으로 충돌 발생시빈 공간을 찾아 나서는 탐사 방식으로 탐사 방식에 따라 Linear probing, Qudratic probing, double hasing 등이 사용 되는데 이 중에서 가장 단순한 Linear probing의 경우 충돌이 발생할 때 마다 한 칸씩 아래로 빈 공간을 찾아 탐색에 나선다. 그림 처럼 빈 공간이 많다면 금방 자리를 찾지만 아닌 경우 계속 탐사를 하게 되므로 효율성이 급격하게 떨어진다는 단점이 있다.

HashMap 클래스를 보면 기본 용량은 16, 로드팩터는 0.75를 기본으로 사용하고 있다. 기본 용량은 버킷의 수와 같고 로드팩터는 (데이터의 개수)/(기본용량)을 의미하는데 로드팩터의 값에 도달하게 되면 버킷의 수를 동적으로 2배 확장하게 된다.
위의 예시로 들면 기본 용량은 16이기 때문에 데이터의 개수가 12개가 차면 버킷의용량은 16 -> 32로 늘리는 과정이 일어남.. 여기서 바로 Map을 조심히 사용해야 되는 이유가 나타나게 되는데 이때 원래 버킷에 있던 것을 새로운 버킷에다 옮기는 과정이 일어나고 이 과정이 성능에 악영향을 끼치게 된다.

출처.
https://sabarada.tistory.com/57
'자바' 카테고리의 다른 글
| WebClient의 onStatus()내 코드를 TypeToken 을 활용하여 중복을 피해보자. (0) | 2021.09.27 |
|---|---|
| 모던 자바 - Reactive Programming 리액티브 프로그래밍 - java 9 Flow (0) | 2021.08.25 |
| 자바 Stream (바이트기반스트림/문자열기반스트림), IO 입출력 (0) | 2021.07.02 |
| 자바 객체의 생성과정(라이플 사이클) / Strong Reference & Weak Reference / 객체와 메모리 (0) | 2021.06.25 |
| Java Volatile And Atomic - 멀티스레딩 환경에서.. (0) | 2021.05.18 |