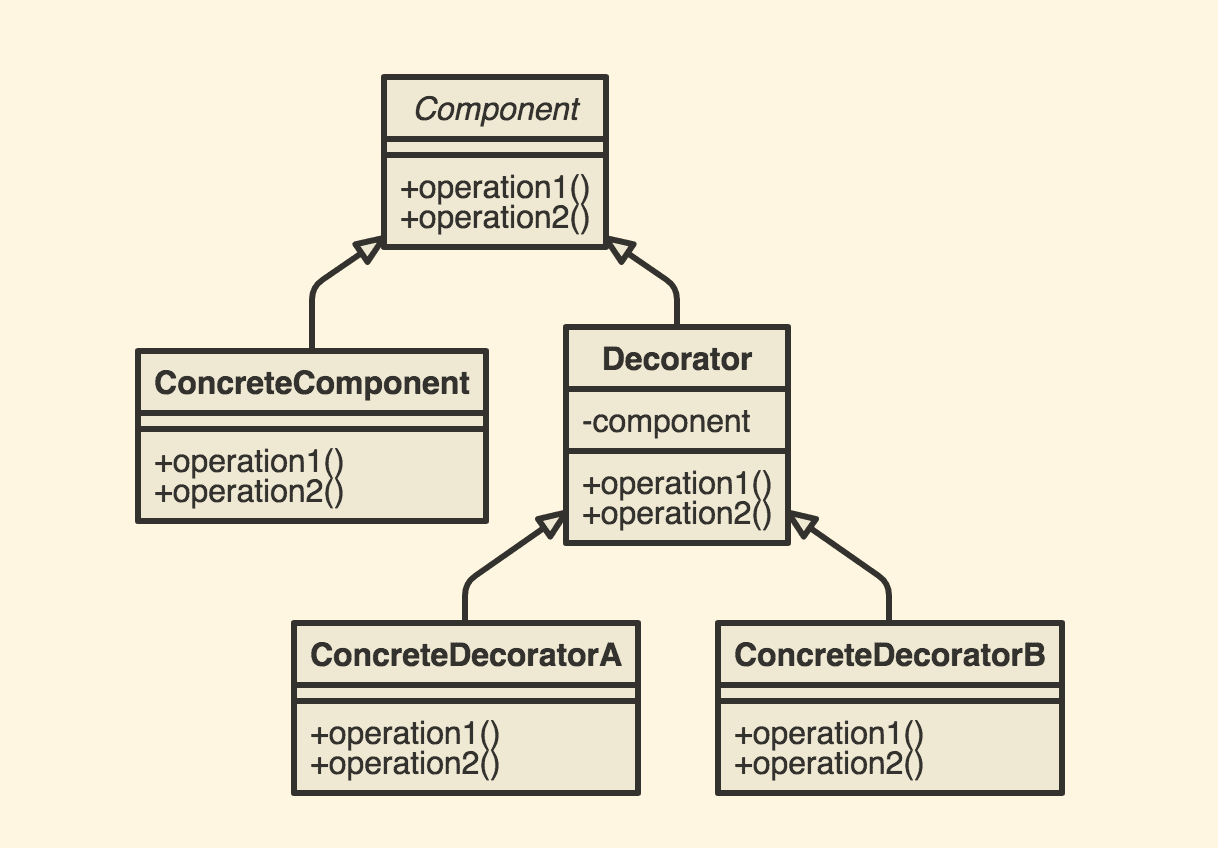
하루 그리고 반나절을 투자해 Spring Batch를 Spring Cloud Data Flow로 관리하려고 했다. 배치 잡 실행과 모니터링을 중앙에서 관리하고, UI도 심플하니 맘에 들어서였다. 그러나 결론은 실패..... 실패한 이유는 사실 프로젝트 일정에 맞추기엔 docker에 대한 사전 지식 부족으로 시간을 무한정 투자할 수가 없어서였다.
우선 SCDF설치를 하는 방법엔 여러가지가 있는데 (Docker Compose, Cloud Foundry, Kubernetes) 그 중에서 나는 docker를 이용해 로컬에 설치하는 방법을 택했다.
https://dataflow.spring.io/docs/installation/local/docker/
Spring Cloud Data Flow(SCDF) 서버에 배치 잡 애플리케이션을 등록하려면 다음과 같은 단계를 따를 수 있다.
- 배치 잡 애플리케이션 빌드
- Spring Batch를 사용하여 배치 잡을 작성합니다.
- 배치 잡 애플리케이션을 빌드하여 실행 가능한 JAR 파일을 생성합니다.
- SCDF 서버 설치
- 도커로 설치
- 애플리케이션 등록
- SCDF 서버 대시보드에서 "Create App" 버튼을 클릭하여 애플리케이션을 등록합니다.
"Type"을 "batch"로 선택하고, "Name"에 애플리케이션 이름을 입력하고, "URI"에 빌드한 JAR 파일의 경로를 입력합니다. (애플리케이션을 등록하면 SCDF 서버에 배치 잡 애플리케이션을 등록한 것)
- SCDF 서버 대시보드에서 "Create App" 버튼을 클릭하여 애플리케이션을 등록합니다.
- 배치 잡 실행
- SCDF 서버 대시보드에서 배치 잡 애플리케이션을 선택하고 실행을 시작합니다.
- 실행 구성 및 배치 잡 인수를 지정할 수 있습니다.
컴퓨터에 docker설치도 안되어 있던 터라 도커부터 설치를 해주고..
아래 docker-compose 파일을 실행해준다. 해당 파일에는 mysql, rabbitmq, dataflow-server, skipper-server, promateus, grafana 서비스를 등록한 내용이 담겨있다. spring cloud data flow를 설치하려면 db, messaging, dataflow-server,skipper-server가 필요하고 scheduling을 위해선 promateus, grafana 설정이 추가로 필요하다.
version: '3'
services:
mysql:
image: mysql:5.7.25
container_name: dataflow-mysql
environment:
MYSQL_DATABASE: dataflow
MYSQL_USER: root
MYSQL_ROOT_PASSWORD: rootpw
networks:
- dataflow-network
expose:
- '3306'
ports:
- '3306:3306'
rabbitmq:
image: rabbitmq:3.7.17-management-alpine
container_name: dataflow-rabbitmq
networks:
- dataflow-network
ports:
- '5672:5672'
- '15672:15672'
dataflow-server:
image: springcloud/spring-cloud-dataflow-server:2.2.1.RELEASE
container_name: dataflow-server
volumes:
- "./tmp:/tmp"
- "./workspace:/workspace"
networks:
- dataflow-network
ports:
- "9393:9393"
environment:
- spring.cloud.dataflow.applicationProperties.stream.spring.rabbitmq.host=rabbitmq
- spring.cloud.skipper.client.serverUri=http://skipper-server:7577/api
- spring.cloud.dataflow.applicationProperties.stream.management.metrics.export.prometheus.enabled=true
- spring.cloud.dataflow.applicationProperties.stream.spring.cloud.streamapp.security.enabled=false
- spring.cloud.dataflow.applicationProperties.stream.management.endpoints.web.exposure.include=prometheus,info,health
- spring.cloud.dataflow.grafana-info.url=http://localhost:3000
- SPRING_DATASOURCE_URL=jdbc:mysql://mysql:3306/dataflow
- SPRING_DATASOURCE_USERNAME=root
- SPRING_DATASOURCE_PASSWORD=rootpw
- SPRING_DATASOURCE_DRIVER_CLASS_NAME=org.mariadb.jdbc.Driver
depends_on:
- rabbitmq
entrypoint: "./wait-for-it.sh mysql:3306 -- java -jar /maven/spring-cloud-dataflow-server.jar"
skipper-server:
image: springcloud/spring-cloud-skipper-server:2.1.2.RELEASE
container_name: skipper
volumes:
- "./tmp:/tmp"
- "./workspace:/workspace"
networks:
- dataflow-network
ports:
- "7577:7577"
- "9000-9010:9000-9010"
- "20000-20105:20000-20105"
environment:
- SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_LOCAL_ACCOUNTS_DEFAULT_PORTRANGE_LOW=20000
- SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_LOCAL_ACCOUNTS_DEFAULT_PORTRANGE_HIGH=20100
- SPRING_DATASOURCE_URL=jdbc:mysql://mysql:3306/dataflow
- SPRING_DATASOURCE_USERNAME=root
- SPRING_DATASOURCE_PASSWORD=rootpw
- SPRING_DATASOURCE_DRIVER_CLASS_NAME=org.mariadb.jdbc.Driver
entrypoint: "./wait-for-it.sh mysql:3306 -- java -Djava.security.egd=file:/dev/./urandom -jar /spring-cloud-skipper-server.jar"
# Grafana is configured with the Prometheus datasource.
# Use `docker exec -it prometheus /bin/sh` to log into the container
prometheus:
image: springcloud/spring-cloud-dataflow-prometheus-local:2.2.1.RELEASE
container_name: prometheus
volumes:
- 'scdf-targets:/etc/prometheus/'
networks:
- dataflow-network
ports:
- '9090:9090'
depends_on:
- service-discovery
# The service-discovery container. Required for Prometheus setup only
# Use `docker exec -it service-discovery /bin/sh` to log into the container
service-discovery:
image: springcloud/spring-cloud-dataflow-prometheus-service-discovery:0.0.4.RELEASE
container_name: service-discovery
volumes:
- 'scdf-targets:/tmp/scdf-targets/'
networks:
- dataflow-network
expose:
- '8181'
ports:
- '8181:8181'
environment:
- metrics.prometheus.target.cron=0/20 * * * * *
- metrics.prometheus.target.filePath=/tmp/scdf-targets/targets.json
- metrics.prometheus.target.discoveryUrl=http://dataflow-server:9393/runtime/apps
- metrics.prometheus.target.overrideIp=skipper-server
- server.port=8181
depends_on:
- dataflow-server
# Grafana SCDF Prometheus pre-built image:
grafana:
image: springcloud/spring-cloud-dataflow-grafana-prometheus:2.2.1.RELEASE a
container_name: grafana
networks:
- dataflow-network
ports:
- '3000:3000'
networks:
dataflow-network:
volumes:
scdf-targets:
docker -f XXX.yml up
명령어를 통해 위 파일을 실행해주면 아래와 같이 http://localhost:9393/dashboard/ 에서 Data Flow 화면을 확인할 수 있다.
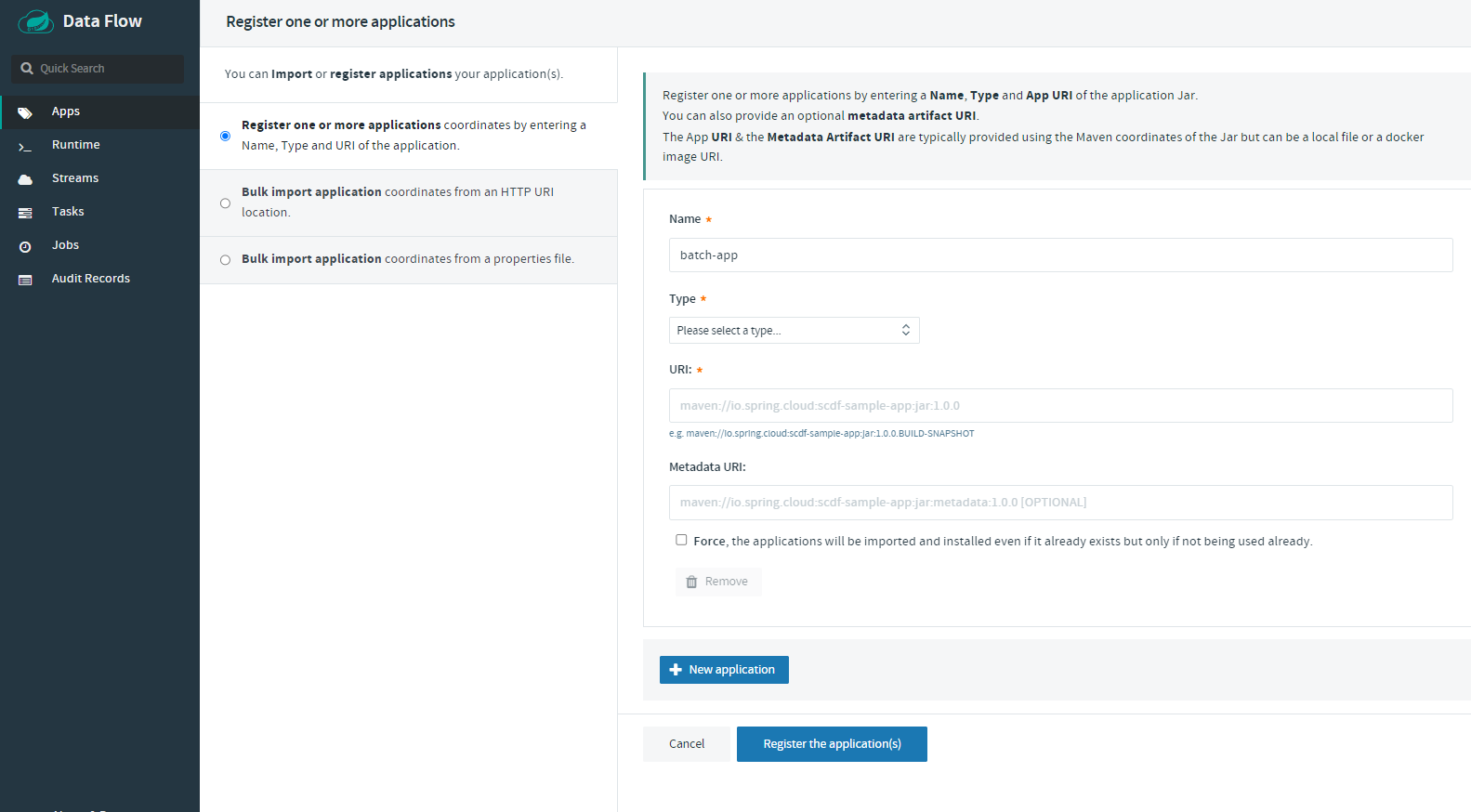
여기서 더 이상의 진행은 중단했다. APP을 등록하는 것에서 애를 먹기도 먹거니와 이걸 결국에는 운영 EC2 환경에서 다양한 변수들을 고려하여 세팅을 해줘야 하는데 허들이 꽤나 있을 것으로 예상되었다. 솔직히 이것만 붙잡고 하고 싶은 마음이 굴뚝 같았으나 (승부욕 발동) 새로운 기술을 써보겠다는 개인적인 사리사욕보다는 우선은 프로젝트 일정에 맞추는 것 더 중요하다 판단되어 일단 이 정도까지 알아본 것으로 마무리하고, 원래 계획대로 Jenkins에서 Spring Batch를 실행하기로.. (쥬륵)너무 아쉽고, 꼭 프로젝트 마치고 다시 도전해봐야 겠다.
'스프링 > Spring Batch' 카테고리의 다른 글
| Jenkins Pipeline으로 Spring Batch Jobs 실행해보기 (0) | 2023.03.29 |
|---|---|
| Spring Batch를 사용하며 맞닥뜨린 상황 기록 02 (0) | 2023.02.28 |
| Spring Batch를 사용하며 맞닥뜨린 상황 기록 01 (0) | 2023.02.14 |
| 스프링배치 핵심 개념 체크를 위한 Questions (메타데이터 테이블, skip&retry, chunk oriented, cursor & paging 등) (0) | 2022.11.16 |
| Spring Batch - @JobScope, @StepScope / LocalDate 사용법 (0) | 2022.10.25 |