신규 프로젝트에 참여하게 됐는데, 기존에 만들어 오던 API 서버와는 다른 부분이 있었다.
바로, 신규 서버는 DB에 연결하지 않고 DB에 연결된 API 서버들과 내부 통신해서 데이터를 가져온다는 점이었다.
Frontend 에서 Request를 보내면 2번 서버가 받는데 2번 서버는 아래 케이스의 일을 수행한다.
case
front에서 2번 서버로 request -> 2번은 4번 서버에 api 콜하여 인증 확인을 한다 -> 1번 서버에 api 콜을 해 PostgreSQL 데이터를 2번 서버로 가져와 데이터를 가공(선택) -> 가공한 데이터를 기반으로 3번 서버에 api 호출을 N번 한다. -> N번 호출해서 받은 데이터를 2번에서 가공 -> 완성된 형태의 response를 frontend로 전달
1번 서버 - RDS 디비와 연결 / 4번 서버 - 인증 서버로 RDS 디비와 연결 / 3번 서버 - Elasticsearch 검색엔진으로부터 데이터를 가져옴
나는 2번 서버 개발을 맡게 되었는데 3번 서버로 날린 여러 API 호출 결과들을 빠르게 조합해서 Front로 전달해야 했기 때문에 비동기로 해당 작업들을 수행하는 것이 좋겠다고 판단하였다.
기존에는 RestTemplate과 모던 자바의 CompletableFuture 조합으로 비동기를 구현했었지만, 이번 프로젝트에는 새로운 기술을 익혀보고 싶어 WebFlux 를 이용해 보기로 했다. 그런데 WebFlux가 어떤건지 대충은 알았지만 정확하게 무엇인지, 구현하는 방법도 모른다는 문제점이.....
이제부터 리액트 프로그래밍에 대해 알아보고, 이것을 신규 프로젝트에 적용할 수 있는지, 할 수 있다면 어떻게 할 수 있는지 알아보도록 한다.
어려움이 닥칠 때 마다 찾는 '모던 자바 인 액션'
다시 이 책을 펼쳤고, 먼저 리액티브 프로그래밍에 대해 자세히 공부해보는 것이 좋겠다고 생각하여 이렇게 포스팅을 하게 되었다. WebFlux를 도입하기 전 "Reactor"에 대한 이해가 선행되어야 한다 해서 "Reactor"에 대해 먼저 알아봤다.
결론은 신규 프로젝트에 적용을 하진 못했지만, 관련해서 알아봤던 내용들을 정리해보겠다.
Reactive Programming
리액티브 시스템과 리액티브 프로그래밍은 다른 개념으로 리액티브 시스템은 시스템 레벨에서 아키텍트와 DevOps를 위한 생산성을 제공한다. 리액티브 프로그래밍은 리액티브 시스템의 구현 수준의 하위집합으로, 내부 로직 및 데이터 흐름 관리를 위한 구성요소 단계에서 높은 생산성을 제공한다.
정의
데이터 흐름과 전달에 관한 프로그래밍 패러다임
리액티브 스트림을 사용하는 프로그래밍
리액티브 스트림 ? 잠재적으로 무한의 비동기 데이터를 순서대로 그리고 블록하지 않는 역압력을 전제해 처리하는 표준 기술
역압력 (Back Pressure) ? 발행-구독 프로토콜에서 이벤트 스트림의 구독자가 발행자가 이벤트를 처리하는 속도보다 느린 속도로 이벤트를 소비하면서 문제가 발생하지 않도록 보장하는 장치
왜 이런 패러다임이 생겼나?
적은 수의 스레드로 동시성을 처리하고 더 적은 하드웨어 리소스로 확장할 수 있는 비차단 웹 스택이 필요하다는 것
Servlet 3.1에서 non-blocking I/O를 위한 API를 제공했지만 이 API의 사용은 synchronous 이거나 blocking인 ServletAPI와 멀어지는 개념이었다.
Java 8에 람다 표현식이 추가됨
Java 8에 람다 표현식을 추가되면서 Fuctional Programming이 가능하게 되었고, 이것은 비동기 논리의 선언적 구성을 허용하는 non-blocking 애플리케이션에 대한 이점입니다.
빅데이터/모바일부터 클라우드 기반 클러스터에 이르는 다양한 환경/밀리초 단위의 응답시간을 기대하는 사용패턴에서의 요구사항을 만족시켜 주기 위해
다양한 시스템과 소스에서 들어오는 데이터 항목 스트림을 비동기적으로 처리해서 문제를 해결한다.
Reactive의 속성 4가지 Keyword (핵심원칙)
반응성: 일정하고 예상할 수 있는 빠른 반응시간
회복성: 장애가 전파되지 않고 복구된다.
탄력성: 작업량의 변화와 무관하다. (병목현상) -> 작업 부하 발생시 관련 컴포넌트에 할당된 자원 수 늘린다.
메시지기반 : 컴포넌트 간의 약한 결합, 고립, 위치 투명성이 유지되도록 시스템은 비동기 메시지 전달에 의존
JDK에서 리액티브 프로그래밍을 제공하는 기술
RxJava
Project Reactor
Spring Framework 5.0
RxJava
자바로 리액티브 프로그래밍을 할 수 있는 라이브러리
비동기 프로그래밍과 함수형 프로그래밍 기법을 활용한다
복잡한 비동기 프로그램을 쉽게 개발할 수 있게 해준다.
java.util.concurrent.Flow 클래스
자바 9에서는 리액티브 프로그래밍을 제공하기 위해 Flow클래스를 추가했다.
리액티브 스트림 프로젝트의 표준에 따라 발행-구독 모델을 지원
Akka, RxJava등의 리액티르 라이브러리는 Flow 클래스에 정의된 인터페이스를 구현한다.
Flow클래스의 인터페이스
Publisher : 항목 발행
Subscriber : Publisher가 발행한 항복을 한개 또는 여러개 소비
Subscription : 위 소비 과정을 정적 메서드로 관리 / Publisher와 Subscriber 사이의 제어 흐름, 역압력 관리
Processor : 프로세서는 게시자와 구독자 사이에 있는 구성 요소로써 Publisher에 시그널을 요청하거나 아이템을 Subscriber에게 Push함
public interface Subscriber<T> {
void onSubscribe(Subscription s); // 항상 처음 호출됨
void onNext(T t); // 2번째로 호출되는 데 여러 번 호출될 수 있음
void onComplete(); // 더 이상의 데이터가 없고 종료됨을 알림
void onError(Throwable t); // Publisher에 장애가 발생했을 때 호출함
}
Subscriber 인터페이스는 Publisher가 관련 이벤트를 발행할 때 호출할 수 있도록 콜백 메서드 네개를 정의한다.
Subscriber가 Publisher에 자신을 등록할 때 Publisher는 처음으로 onSubscribe 메서드를 호출해 Subscription 객체를 전달한다. Subscription 인터페이스는 메서드 두 개를 정의한다. Subscription은 첫 번째 메서드로 Publisher에게 주어진 개수의 이벤트를 처리할 준비가 되었음을 알릴 수 있다. 두 번째 메서드로는 Subscription을 취소, 즉 Publisher에게 더 이상 이벤트를 받지 않음을 통지한다.
public interface Subscription {
void request(long n);
void cancel();
}
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {}
Subscriber::onNext() 메서드를 사용하여 게시자는 항목을 프로세서에 푸시하고 프로세서는 항목을 구독자에 푸시
Subscription::request() 메서드를 사용하여 프로세서는 게시자에게 항목을 요청, 구독자는 프로세서에 항목을 요청
게시자 및 프로세서는 멀티스레딩을 위한 실행자를 정의하고, request() 및 onNext() 메서드가 비동기적으로 작동
Processor는 Subscriber와 Processor가 요청한 항목의 수요량이 다른 경우 항목을 저장하기 위한 데이터 버퍼 가짐
자바 9 플로 API를 직접 이용하는 첫 리액티브 애플리케이션 ( from 모던 자바 인 액션)
- TempInfo. 원격온도계로 0에서 99사이 온도를 보고
- TempSubscriber 각 도시에 설치된 센서가 보고한 온도 스트림 출력
import java.util.Random;
public class TempInfo {
public static final Random random = new Random();
private final String town;
private final int temp;
public TempInfo(String town, int temp) {
this.town = town;
this.temp = temp;
}
public static TempInfo fetch(String town) {
if (random.nextInt(10) == 0) { // 10분의 1 확률로 작업 실패
throw new RuntimeException("Error!");
}
return new TempInfo(town, random.nextInt(100)); // 임의의 화씨 온도를 반환
}
@Override
public String toString() {
return town + " : " + temp;
}
public int getTemp() {
return temp;
}
public String getTown() {
return town;
}
}
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Flow.Subscriber;
import java.util.concurrent.Flow.Subscription;
public class TempSubscription implements Subscription {
private final Subscriber<? super TempInfo> subscriber;
private final String town;
private static final ExecutorService executor = Executors.newSingleThreadExecutor();
public TempSubscription (Subscriber<? super TempInfo> subscriber, String town) {
this.subscriber = subscriber;
this.town = town;
}
@Override
public void request(long n) {
executor.submit( () -> {
for (long l = 0L; l < n; l++) {
try {
subscriber.onNext(TempInfo.fetch(town)); // 현재 온도를 subscriber로 전달
} catch (Exception e) {
subscriber.onError(e); // 실패하면 subscriber로 에러 전달
break;
}
}
});
}
@Override
public void cancel() {
subscriber.onComplete(); // 구독취소되면 subscriber로 전달
}
}
ExecutorService는 비동기 모드에서 실행 중인 작업을 단순화하는 JDK API
일반적으로 ExecutorService는 스레드 풀과 여기에 태스크를 할당하기 위한 API를 자동으로 제공합니다.
public class TempSubscriber implements Flow.Subscriber<TempInfo> {
private Flow.Subscription subscription;
@Override
public void onSubscribe(Flow.Subscription subscription) {
this.subscription = subscription;
subscription.request(1);
}
@Override
public void onNext(TempInfo tempInfo) {
System.out.println(tempInfo);
subscription.request(1);
}
@Override
public void onError(Throwable t) {
System.err.println(t.getMessage());
}
@Override
public void onComplete() {
System.out.println("Done!");
}
}
Processor는 Subscriber이며 동시에 Publisher다.
Processor의 목적은 Publisher를 구독한 다음 수신한 데이터를 가공해 다시 제공하는 것이다.
화씨를 섭시로 변환하는 Processor
import java.util.concurrent.Flow.*;
public class TempProcessor implements Processor<TempInfo, TempInfo> {
private Subscriber<? super TempInfo> subscriber;
@Override
public void subscribe(Subscriber<? super TempInfo> subscriber) {
this.subscriber = subscriber;
}
@Override
public void onNext(TempInfo temp) {
subscriber.onNext(new TempInfo(temp.getTown(),
(temp.getTemp() - 32) * 5 / 9));
}
@Override
public void onSubscribe(Subscription subscription) {
subscriber.onSubscribe(subscription);
}
@Override
public void onError(Throwable throwable) {
subscriber.onError(throwable);
}
@Override
public void onComplete() {
subscriber.onComplete();
}
Publisher의 subscribe 메서드는 업스트림 Subscriber를 Processor로 등록하는 동작을 수행한다.
import java.util.concurrent.Flow.Publisher;
public class Main {
public static void main(String[] args) {
getCelsiusTemperatures("New York").subscribe(new TempSubscriber());
}
private static Publisher<TempInfo> getCelsiusTemperatures(String town) {
return subscriber -> {
TempProcessor processor = new TempProcessor();
processor.subscribe(subscriber);
processor.onSubscribe(new TempSubscription(processor, town));
};
}
}
이것도 마찬가지로 스택을 이용하는 문제이고, .peek()메소드를 이용해 맨 상단의 수를 체크해서 같지 않은 경우엔 .push() 같으면 .pop()을 시킨다. 다차원 배열도 같이 잘 다뤄줘야 하는데 int[N][N] box = new int[][]; 라고 가정하면 box.length는 행의 개수, box[3].length 이렇게 하면 열의 개수를 알 수 있다.
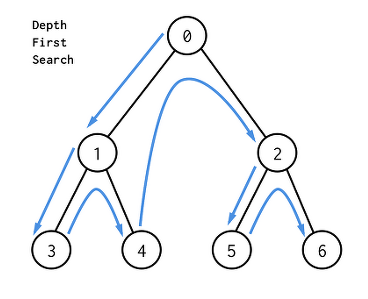
DFS
개념정리
전위순회 : 부모 - 왼 - 오 (0 -> 1 -> 3 -> 4 -> 2 -> 5 -> 6)
중위순회 : 왼 - 부모 - 오 (3 -> 1 -> 4 -> 0 -> 5 -> 2 -> 6)
후위순회 : 왼 - 오 - 부모 (3 -> 4 -> 1 -> 5 -> 6 -> 2 -> 0)
class Node {
int data;
Node lt;
Node rt;
public Node (int data) {
this.data = data;
lt=rt=null;
}
}
public class Main {
Node root;
public void DFS(Node root) {
if (root == null) return;
else {
// System.out.println(root.data + " "); // 전위순회
DFS(root.lt); // 왼쪽으로
// System.out.println(root.data + " "); // 중위순회
DFS(root.rt); // 오른쪽으로
// System.out.println(root.data + " "); // 후위순회
}
}
public static void main(String args[]) {
Main tree = new Main();
tree.root = new Node(1);
tree.root.lt = new Node(2);
tree.root.rt = new Node(3);
tree.root.lt.lt = new Node(4);
tree.root.lt.rt = new Node(5);
tree.root.rt.lt = new Node(6);
tree.root.rt.rt = new Node(7);
tree.DFS(tree.root);
}
문제 1 ) 자연수 N이 주어지면 1부터 N까지의 원소를 갖는 집합의 부분집합을 모두 출력하는 프로그램을 작성 (공집합 제외)
3 -> 1,2,3 / 1,2 / 1,3 / 1 / 2,3 / 2 / 3
1,2,3 에서 각 자연수는 집합에 들어갈 수 있다/없다 (LT / RT) 두가지 경우의수를 가진다.
class Main {
static int n;
static int[] ch;
public void DFS(int L) {
if (L == n+1) {
// 1로 표시된 인덱스를 표시해준다.
String tmp = "";
for (int i = 1; i <= n ; i++) {
if (ch[i] == 1) tmp += (i + " ");
}
if (tmp.length() > 0) {
System.out.println(tmp);
}
} else {
ch[L] = 1;
DFS(L+1) // 사용한다 (왼쪽)
ch[L] = 0;
DFS(L+1) // 사용하지 않는다 (오른쪽)
}
}
public static void main(String[] args) {
Main T = new Main();
n = 3;
ch = new int[n+1];
T.DFS(1);
}
}
여기서 버전 정보가 Client와 Server로 나뉘어져 있는 이유는 도커는 하나의 실행파일이지만 실제로 클라이언트와 서버 역할을 할 수 있기 때문이다. 도커 커맨드를 입력하면 클라이언트에서 도커 서버로 명령을 전송하고 결과를 받아 터미널에 출력한다. 기본값이 도커 서버의 소켓을 바라보고 있기 때문에 터미널에서 명령어를 입력했을 때 바로 명령을 내리는 것 같은 느낌을 받는다. 이게 가상 서버에 설치된 도커가 동작하는 이유!
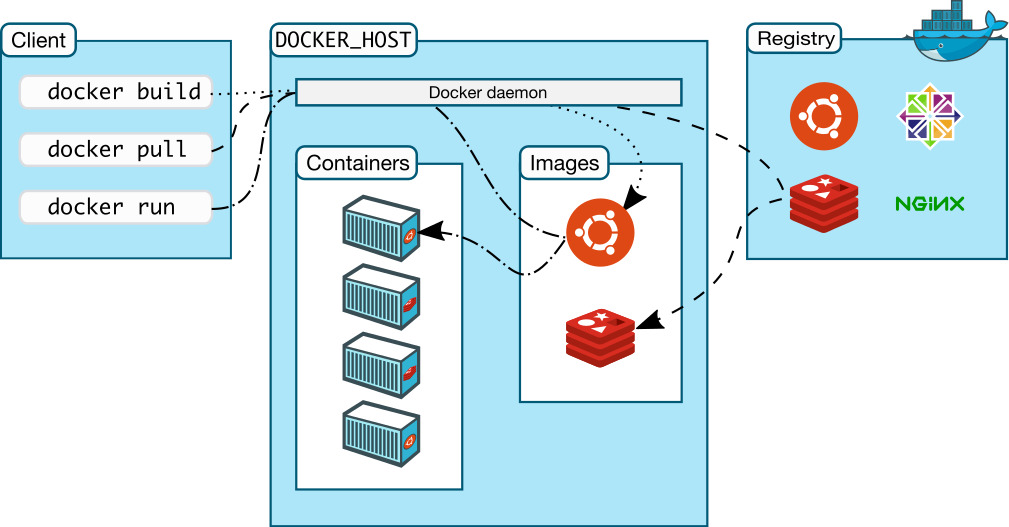
Docker 클라이언트 는 Docker 컨테이너를 빌드, 실행 및 배포하는 무거운 작업을 수행 하는 Docker 데몬 과 통신합니다. Docker 클라이언트와 데몬 은 동일한 시스템에서 실행되거나 Docker 클라이언트를 원격 Docker 데몬에 연결할 수 있습니다. Docker 클라이언트와 데몬은 UNIX 소켓 또는 네트워크 인터페이스를 통해 REST API를 사용하여 통신합니다.
도커 데몬
Docker 데몬( dockerd)은 Docker API 요청을 수신하고 이미지, 컨테이너, 네트워크 및 볼륨과 같은 Docker 객체를 관리합니다. 데몬은 Docker 서비스를 관리하기 위해 다른 데몬과 통신할 수도 있습니다.
도커 클라이언트
Docker 클라이언트( docker)는 많은 Docker 사용자가 Docker와 상호 작용하는 기본 방법입니다. 와 같은 명령을 사용할 때 docker run클라이언트는 이러한 명령을 로 보냅니다 dockerd. 이 docker명령은 Docker API를 사용합니다. Docker 클라이언트는 둘 이상의 데몬과 통신할 수 있습니다.
도커 레지스트리
Docker 레지스트리 는 Docker 이미지를 저장합니다. Docker Hub는 누구나 사용할 수 있는 공개 레지스트리이며 Docker는 기본적으로 Docker Hub에서 이미지를 찾도록 구성되어 있습니다. 자신의 개인 레지스트리를 실행할 수도 있습니다. docker pull또는 docker run명령 을 사용하면 구성된 레지스트리에서 필요한 이미지를 가져옵니다. docker push명령 을 사용하면 이미지가 구성된 레지스트리로 푸시됩니다.
이미지
이미지 도커 컨테이너를 만들기위한 읽기 전용 템플릿입니다. 종종 이미지는 몇 가지 추가 사용자 정의와 함께 다른 이미지를 기반으로 합니다. 예를 들어, 이미지를 기반으로 하는 이미지를 빌드할 수 ubuntu 있지만 Apache 웹 서버와 애플리케이션은 물론 애플리케이션을 실행하는 데 필요한 구성 세부 정보도 설치합니다.
자신만의 이미지를 만들거나 다른 사람이 만들고 레지스트리에 게시한 이미지만 사용할 수 있습니다. 고유한 이미지를 빌드하려면 이미지를 만들고 실행하는 데 필요한 단계를 정의하는 간단한 구문 으로 Dockerfile 을 만듭니다. Dockerfile의 각 명령은 이미지에 계층을 생성합니다. Dockerfile을 변경하고 이미지를 다시 빌드하면 변경된 레이어만 다시 빌드됩니다. 이것은 다른 가상화 기술과 비교할 때 이미지를 가볍고 작고 빠르게 만드는 부분입니다.
컨테이너
컨테이너는 이미지의 실행 가능한 인스턴스입니다. Docker API 또는 CLI를 사용하여 컨테이너를 생성, 시작, 중지, 이동 또는 삭제할 수 있습니다. 컨테이너를 하나 이상의 네트워크에 연결하거나, 스토리지를 연결하거나, 현재 상태를 기반으로 새 이미지를 생성할 수도 있습니다.
기본적으로 컨테이너는 다른 컨테이너 및 해당 호스트 시스템과 비교적 잘 격리되어 있습니다. 컨테이너의 네트워크, 저장소 또는 기타 기본 하위 시스템이 다른 컨테이너나 호스트 시스템과 얼마나 격리되었는지 제어할 수 있습니다.
컨테이너는 이미지와 컨테이너를 만들거나 시작할 때 제공하는 구성 옵션으로 정의됩니다. 컨테이너가 제거되면 영구 저장소에 저장되지 않은 상태 변경 사항이 사라집니다.
도커를 실행하는 명령어는 다음과 같습니다.
docker run [OPTIONS] IMAGE[:TAG|@DIGEST] [COMMAND] [ARG...]
컨테이너는 ubuntu 16.04로 예제와 동일하게 실행했고, local에 존재하지 않아서 이미지를 pull하였다.
$ docker run ubuntu:16.04
컨테이너는 생성되자마자 종료되었다.
컨테이너는 프로세스이기 때문에 실행중인 프로세스가 없으면 컨테이너는 종료된다.
/bin/bash 명령어를 사용하여 컨테이너를 실행
$ docker run --rm -it ubuntu:16.04 /bin/bash
바로 이전에 이미지를 다운 받았기 때문에 이미지를 다운로드 하는 화면 없이 바로 실행되었다.
exit 명령어를 통해 bash 쉘을 종료하면 컨테이너도 같이 종료됩니다.
redis 컨테이너 생성
메모리 기반의 다양한 기능을 가진 스토리지 redis,
redis 컨테이너를 실행해보자!
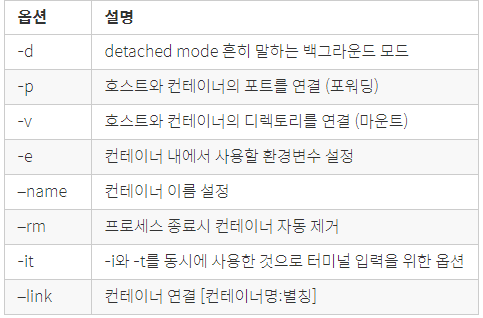
-d : 백그라운드 모드
-p : 컨테이너의 포트를 호스트의 포트로 연결
docker run -d -p 1234:6379 redis
$ telnet localhost 1234 // telnet이 없어서 brew로 설치해주었다.
Trying ::1...
Connected to localhost.
Escape character is '^]'.
//여기서부터 명령어를 입력해주면 된다.
set mykey hello
+OK
get my key
$5
hello
quit
백그라운드 모드에서 동작하고 있던 컨테이너. -p 로 동작시킨 컨테이너이기 때문에 호스트의 1234 포트를 컨테이너의 6379 포트로 연결하였다. 따라서 localhost의 1234 포트로 접속하게 되면 redis를 바로 사용할 수 있게 된다.
MySQL 컨테이너 생성
-e : 환경변수 설정
--name : 컨테이너에 읽기 어려운 ID 대신 쉬운 이름을 부여한다.
$ docker run -d -p 3306:3306 -e MYSQL_ALLOW_EMPTY_PASSWORD=true --name mysql mysql:5.7
$ mysql -h127.0.0.1 -uroot // mysql 도 brew로 설치해주었다.
mysql> show databases;
mysql> quit
MYSQL_ALLOW_EMPTY_PASSWORD 환경변수를 설정하여 패스워드 없이 root 계정을 만들었다.
그 외
$ mysql -h127.0.0.1 -uroot
create database wp CHARACTER SET utf8;
grant all privileges on wp.* to wp@'%' identified by 'wp';
flush privileges;
quit
# run wordpress container docker run -d -p 8080:80 --link mysql:mysql \
-e WORDPRESS_DB_HOST=mysql \
-e WORDPRESS_DB_NAME=wp \
-e WORDPRESS_DB_USER=wp \
-e WORDPRESS_DB_PASSWORD=wp \
wordpress
워드프레스용 데이터베이스를 생성하고 워드프레스 컨테이너를 실행합니다. 호스트의 8080포트를 컨테이너의 80포트로 연결하고 MySQL 컨테이너와 연결한 후 각종 데이터베이스 설정 정보를 환경변수로 입력합니다.
중요한건 MySQL 컨테이너와 연결한다는 것 같다.
<tensorflow>
$ docker run -d -p 8888:8888 -p 6006:6006 teamlab/pydata-tensorflow:0.1
이렇게 여러개의 컨테이너를 실행해보았고, 컴퓨터가 컨테이너 기반의 도커를 이용해 짱짱하게 실행하는 것을 볼 수 있었다.
Map의 무분별한 활용으로 Memory Leak이 운영중인 서비스에 발생할 수 있다 하셨다.
그래서 오늘 스터디 내용의 주제는 Map이다. 몸은 가까웠지만 마음은 멀었던 요놈, 파헤쳐보기로..
아래 내용은 기술 세미나(?)를 위해 내가 준비한 자료들이다.
인터페이스List와 Set을 구현한 컬렉션 클래스들은 많은 공통부분이 있어서,
공통된 부분을 다시 뽑아 Collection 인터페이스를 정의할 수 있었지만
Map인터페이스는 이들과는 다른 형태로 컬렉션을 다루기 때문에 같은 상속 계층도에 포함되지 못한다.
HashMap은Entry 타입을 구현한 Node라는 내부 클래스를 정의하며
키와 값은 별개의 값이 아니라 서로 관련된 값이기 때문에 하나의 클래스로 정의하여 하나의 배열로 다룬다.
키와 벨류는Object 타입이므로 어떠한 객체도 저장할 수 있다.
Node 클래스 자체는 사실상 Java 7의 Entry 클래스와 내용이 같지만,
Java 8에서는 일정 개수 이상이 되면 트리구조를 이용하는 것으로 발전했다.
링크드 리스트 대신 트리를 사용할 수 있도록 하위 클래스인 TreeNode가 있다는 것이 Java 7 HashMap과 다릅니다.
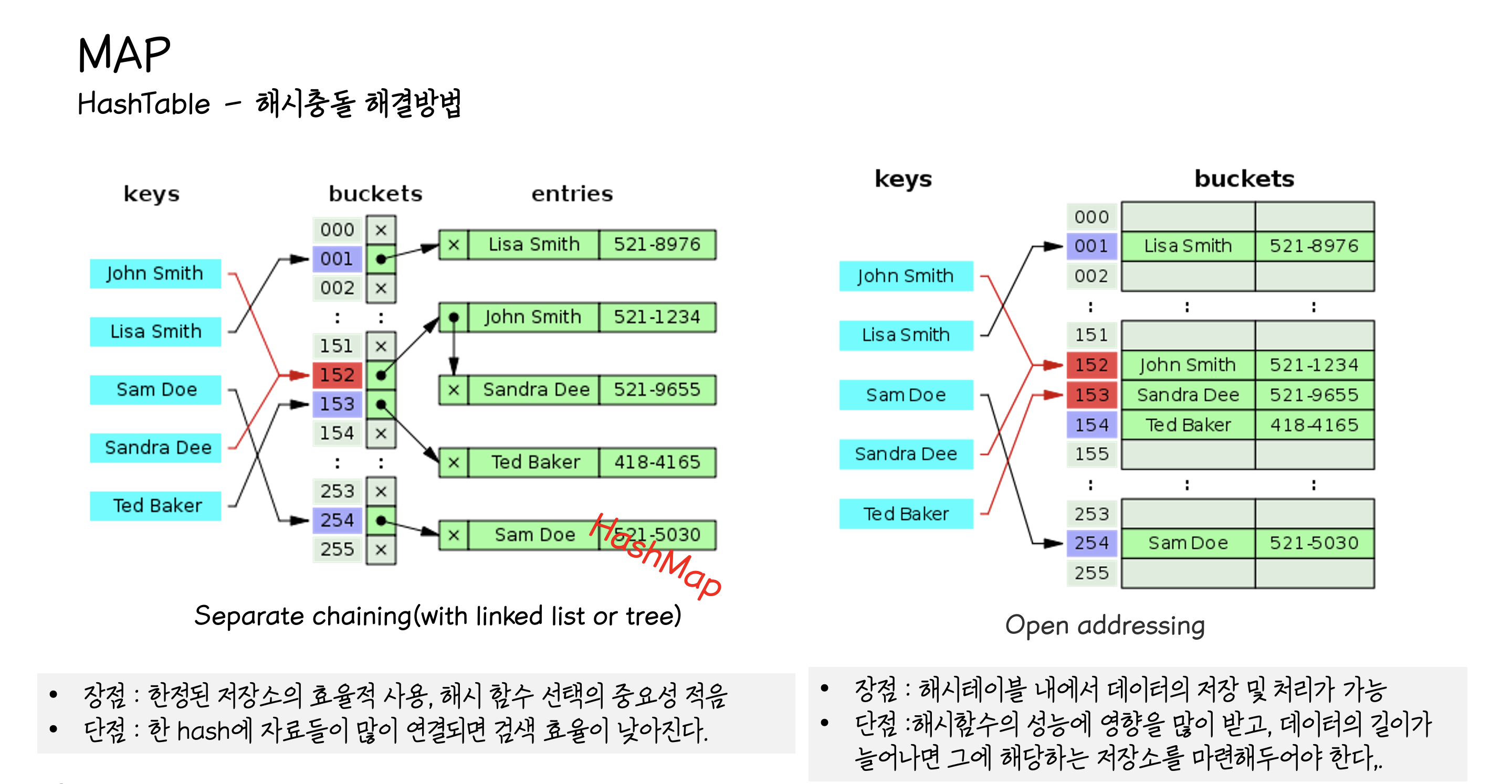
해싱에서 사용하는 자료구조는 배열과 링크드 리스트의 조합으로 되어있다.
저장할 데이터의 키를 해시함수에 넣으면 배열의 한 요소를 얻게 되고,
다시 그곳에 연결되어 있는 링크드 리스트에 저장한다.
예를 들면 주민등록번호의 맨 앞자리인 생년을 기준으로 데이터를 분류해서 10개의 서랍에 나눠담는다.
71,72년생과 같은 70년대 환자들의 데이터는 같은 서랍에 저장하는 식으로
이렇게 분류하여 저장하면 환자의 주민번호로 태어난 년대를 계산해서 어느 서랍에서 찾아야 할지를 쉽게 알 수 있다.
링크드리스트는 크기가 커질수록 검색속도가 떨어지기 때문에
하나의 서랍에 데이터의 수가 많을수록 검색에 시간이 더 걸린다.
배열은 배열의 크기가 커져도,
원하는 요소가 몇 번째에 있는지만 알면 아래의 공식에 의해서 빠르게 원하는 값을 찾을 수 있다.
링크드리스트는 불연속적으로 존재하는 데이터를 서로 연결한 형태로 구성되어 있는데,
리스트의 각 요소(node)들은 자신과 연결된 다음 요소에 대한 참조(주소값)와 데이터로 구성되어 있다.
연속적으로 메모리상에 존재하는게 아니기 때문에
링크드리스트는 불연속적으로 위치한 각 요소들이 서로 연결된 것이라
처음부터 n번째 데이터까지 차례대로 따라가야만 원하는 값을 얻을 수 있다.
그래서 데이터의 개수가 많아질수록 데이터를 읽어 오는 시간이 길어진다는 단점이 존재
키를 있는 그대로 저장하는 경우 다양한 키의 길이 만큼의 크기를 마련해두어야 하기 때문에
일정한 길이의 해시로 변경해야 한다고 했다.
키의 전체 개수와 동일한 크기의 버킷을 가진 해시테이블을 Direct-address table라고한다. Direct-address table의 장점은 키의 개수와 테이블의 크기가 같기 때문에
해시 충돌 문제가 발생하지 않는다다.
Q. 실제 사용하는 키는 몇개 되지 않을 경우에는?
- 전체키100개중에 실제로는 10개의 키만 사용하는데 100개 크기의 테이블을 유지하고 있는 것은 메모리 낭비이다.
따라서 보통의 경우 실제 사용하는 키 개수보다 적은 해시테이블을 운용한다고 한다.
그렇기에 해시 충돌이 발생할 수 밖에 없고, 해시 충돌을 해결하기 위한 다양한 방법들이 고안되었다.
둘 이상의 키에 동일한 인덱스 충돌이 발생할 경우 해결방법에 따라 크게 두가지 형태로 나눈다.
첫번째로는 Separate chaning으로 충돌 발생시 링크드 리스트로 연결하는 방식으로 간단한 해시 함수를 사용하기 때문에 가장 널리 쓰이는 방식.Java HashMap에서 이용하는 방식으로 동일한 버킷의 데이터에 대해 리스트 혹은 트리 자료구조를 이용해서 추가 메모리를 사용하여 다음 데이터의 주소를 저장한다.HashMap은 리스트의 개수가 8개 이상이 되면 트리 자료구조를 사용하게 된다.
두번째는OpenAddressing으로 충돌 발생시빈 공간을 찾아 나서는 탐사 방식으로 탐사 방식에 따라 Linear probing, Qudratic probing, double hasing등이 사용 되는데 이 중에서 가장 단순한 Linear probing의 경우 충돌이 발생할 때 마다 한 칸씩 아래로 빈 공간을 찾아 탐색에 나선다. 그림 처럼 빈 공간이 많다면 금방 자리를 찾지만 아닌 경우 계속 탐사를 하게 되므로 효율성이 급격하게 떨어진다는 단점이 있다.
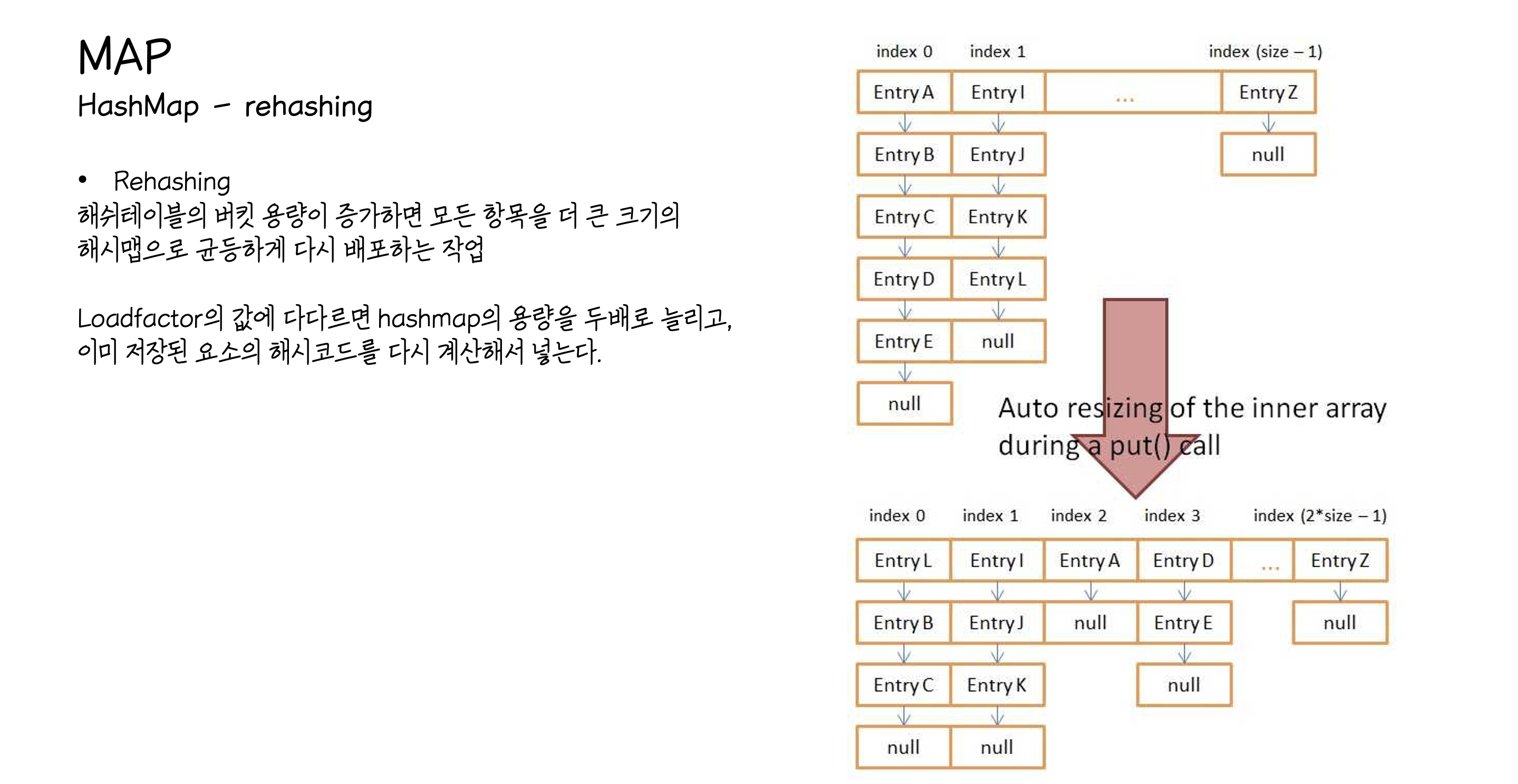
HashMap 클래스를 보면 기본 용량은 16,로드팩터는0.75를 기본으로 사용하고 있다. 기본 용량은 버킷의 수와 같고 로드팩터는(데이터의 개수)/(기본용량)을 의미하는데 로드팩터의 값에 도달하게 되면 버킷의 수를 동적으로 2배 확장하게 된다.
위의 예시로 들면 기본 용량은 16이기 때문에 데이터의 개수가 12개가 차면 버킷의용량은16->32로 늘리는 과정이 일어남.. 여기서 바로 Map을 조심히 사용해야 되는 이유가 나타나게 되는데 이때 원래 버킷에 있던 것을 새로운 버킷에다 옮기는 과정이 일어나고 이 과정이 성능에 악영향을 끼치게 된다.
스트림은 바이트단위로 데이터를 전송하며 입출력 대상에 따라 다음과 같은 입출력 스트림이 있다.
어떠한 대상에 대해서 작업을 할 것인지 그리고 입력을 할 것인지 출력을 할 것인지에 따라서 해당 스트림을 선택해서 사용하면 된다.
이들은 모두 InputStream 또는 OutputStream의 자손들이며, 각각 읽고 쓰는데 필요한 추상메서드를 자신에 맞게 구현해 놓은 것들이다.
IO는 기본적으로 버퍼를 지원하지 않기 때문에, 버퍼를 제공해주는 보조스트림을 이용합니다.
한 문자를 의미하는 char형이 2byte이기 때문에 바이트기반의 스트림으로 2byte인 문자를 처리하는 데는 어려움이 있다.
이 점을 보완하기 위해서 문자기반의 스트림이 제공된다. 문자 데이터를 입출력할 때는 바이트 기반 스트림 대신 문자기반 스트림을 사용한다.
문자기반 스트림이라는 것이 단순히 2byte로 스트림을 처리하는 것만을 의미하지 않는다.
문자 데이터를 다루는데 필요한 또 하나의 정보는 인코딩으로문자기반 스트림, 즉 Reader/Writer 그리고 그 자손들은 여러 종류의 인코딩과 자바에서 사용하는 유니코드간의 변환을 자동적으로 처리해준다.Reader는 틀정인코딩을 읽어서 유니코드로 변환하고 Writer는 유니코드를 특정 인코딩으로 변환하여 저장한다.
객체를 저장한다는 것은 무엇을 의미하는가에 대해서 정리하고 넘아가자면 객체는 클래스에 정의된 인스턴스 변수의 집합입니다.
객체에는 클래스 변수나 메서드가 포함되지 않습니다. 객체는 오직 인스턴스 변수들로만 구성되어 있는데, 그 이유는 인스턴스 변수는 인스턴스마다 다른 값을 가질 수 있어야 하기 때문에 별도의 메모리 공간이 필요하지만 메서드는 변하는 것이 아니라서 메모리를 낭비해 가면서 인스턴스마다 같은 내용의 메서드를 포함시킬 이유가 없습니다,
따라서 객체를 저장한다는 것은 바로 객체의 모든 인스턴스변수의 값을 저장한다는 것이고, 저장한 객체를 다시 생성하려면 객체를 생성한 후에 저장했던 값을 읽어서 생성한 객체의 인스턴스 변수에 저장하면 되는 것
여기서 비효율적인 부분이 보이는데 커널 영역의 데이터를 포르세스 안의 버퍼로 저장하는 일이다. 커널 영역의 버퍼를 직접 전근할 수 있다면 굳이 프로세스 안의 버퍼로 복사하면서 cpu를 낭비하지 않아도 되고,GC 관리도 필요없어지게 된다. 또 하나의 문제는 위 프로세스를 거치는 동안 작업을 요청한 쓰레드가블록킹 된다는 것이다.